Неконтролируемая классификация¶
При добавлении процедуры следует выбрать набор аргументов в соответствии с желаемым методом начальной расстановки центров кластеров.
Вход: растр, параметры, области интереса (только для расстановки центров вручную).
Выход: результат классификации, растр с изображением расстояний.
Необходимо задать желаемое числа кластеров, допустимое число итераций и порог согласованности. Также есть возможность задать дополнительные параметры (см. ниже).
Допустимое количество итераций — максимальное допустимое число итераций кластеризации. Реальное число итераций может быть меньше допустимого, если порог согласованности был достигнут раньше последней итерации. В процессе выполнения процедуры текущие значения порога согласованности отображаются в логе программы.
Если выбрана расстановка центров кластеров вручную, то в качестве входного аргумента надо также передать точки, которые указывают центры кластеров. Области интереса должны быть в той же проекции, что и входной растр, и должны находиться в пределах границ растра. Если выбран случаный способ, программа случайным образом распределит по изображению заданное пользователем число точек.
Если выбрана равномерная расстановка центров кластеров, то перед запуском процедуры следует вычислить статистику по растру, выбрав пункт “Статистика” в его контекстном меню. Центры кластеров будут равномерно распределены вдоль отрезка (начиная от концов) в многомерном пространстве признаков, начальная точка которого имеет координаты по каждой оси, равные разности среднего значения по растру в соответствующем канале и стандартного отклонения в этом же канале. Конечная точка отрезка, аналогично, имеет координаты, каждая из которых равна сумме среднего значения и стандартного отклонения по каналу растра, соответствующему конкретной оси. Этот метод расстановки исходных центров кластеров аналогичен использующемуся в Erdas.
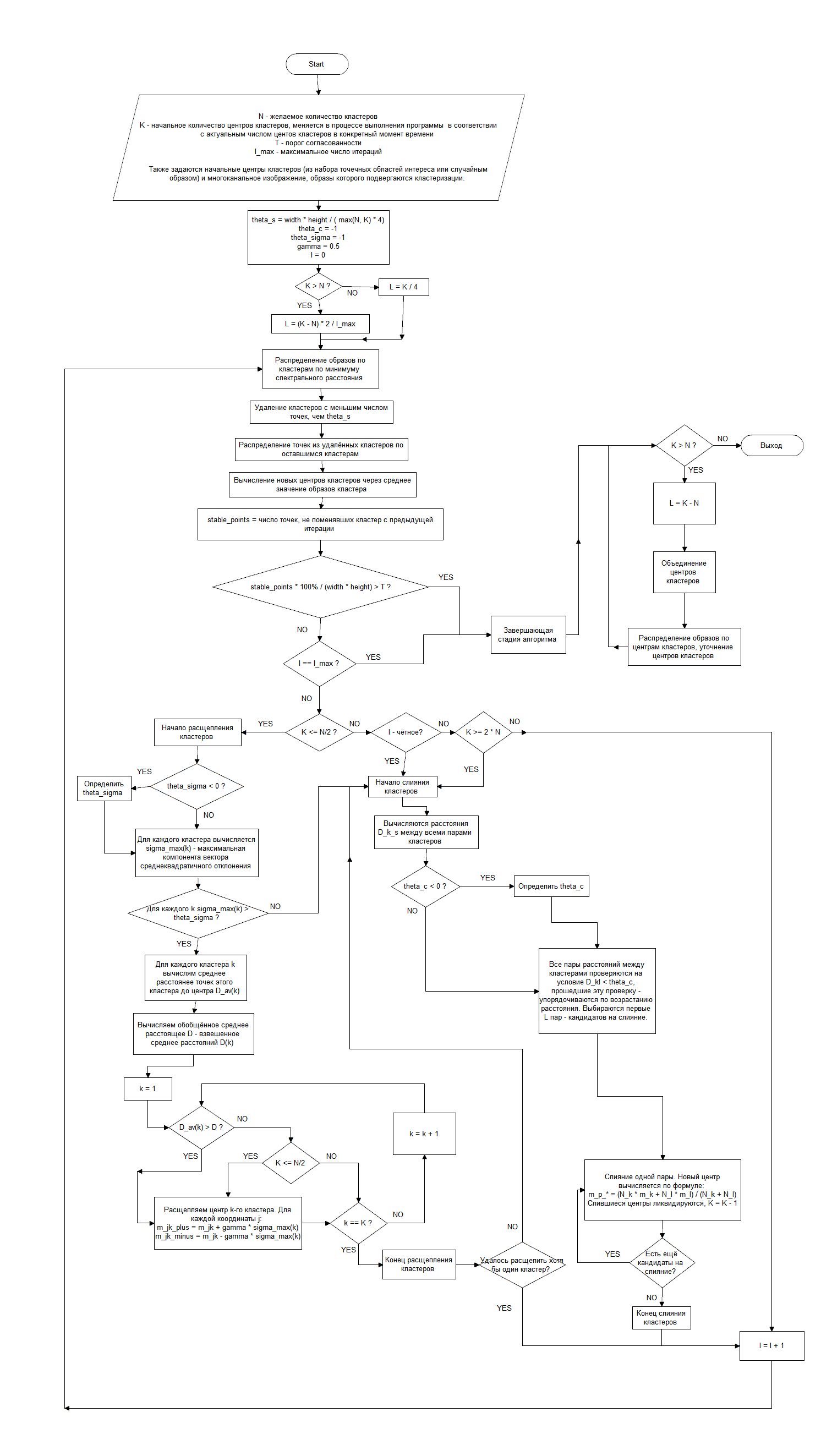
Классификация осуществляется на основании алгоритма кластеризации ISODATA. Кроме того, на каждой итерации алгоритма вычисляется процент точек, не поменявших свой кластер с прошлой итерации, и сравнивается с порогом согласованности, при превышении которого классификация завершается. В процессе классификации появляется и на каждой итерации обновляется окно с таблицей значений этого процента на каждой итерации. Если при завершении классификации актуальное число кластеров оказывается больше желаемого числа кластеров, производится слияние кластеров, пока не будет достигнуто их желаемое число.
Полученный результат классификации содержит информацию о распределении точек изображения по классам. Если для исходного растра построено изображение, то выполняется автоматическое определение цветов классов на основе изображения.
Выходной растр содержит информацию о расстоянии каждой точки изображения до центра кластера, в который она была распределена на последней итерации.
Дополнительные параметры¶
theta_s, theta_sigma, theta_c, L, gamma
Есть возможность задать эти параметры, используемые в алгоритме. Если они не заданы вручную, то gamma = 0.5, а остальные четыре значения вычисляются на основе входных данных алгоритма и собираемых в процессе работы алгоритма статистических данных. Вычисленные значения параметров отображаются в логе программы. Использование этих параметров в алгоритме отображено на блок-схеме.
Блок-схема алгоритма¶